
NVIDIA Parakeet v2 vs OpenAI Whisper:
Top ASR Model Comparison
⏱ 12 min read | 🤖 AI Automation | 🎯 For Decision Makers & Leaders
Introduction: ASR model comparison
Automatic Speech Recognition (ASR) systems have evolved from simple transcription tools into mission-critical enterprise infrastructure. From call centers and media transcription to analytics, assistants, and multilingual applications, ASR model selection directly impacts cost, latency, and scalability.
This ASR model comparison evaluates NVIDIA Parakeet v2 and OpenAI Whisper, two widely adopted speech recognition models, across architecture, benchmarks, latency, throughput, deployment, licensing, and real-world production trade-offs.
At Logassa LLC, we analyze ASR models through a deployment-first lens, focusing on operational efficiency, system scalability, and long-term enterprise viability.
Architecture Overview: ASR model comparison
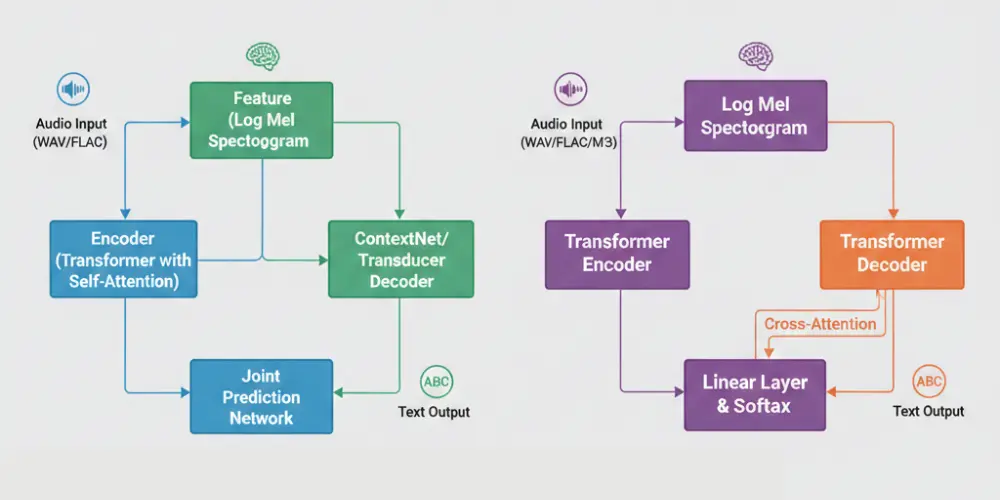
NVIDIA Parakeet v2
Parakeet v2 is built on a FastConformer encoder paired with a Token Duration Transducer (TDT) decoder.
This architecture enables:
- Extremely high GPU throughput
- Low-latency decoding
- Native word-level timestamps
By explicitly predicting token durations, the TDT decoder ensures stable alignment, making Parakeet highly reliable for subtitles, analytics, and time-sensitive.
OpenAI Whisper
Whisper uses a Transformer encoder–decoder architecture, trained end-to-end on massive multilingual datasets.
Key strengths include:
- Strong generalization
- Multilingual speech recognition
- Built-in translation capabilities
However, Whisper relies on autoregressive decoding, which introduces higher latency and lower throughput in enterprise-scale ASR model comparison scenarios
Training Data & Language Support
Parakeet v2 is English-only, trained on curated, high-quality speech datasets optimized for accuracy and inference speed.
Whisper is trained on approximately 680,000 hours of multilingual audio, supporting around 99 languages, including both transcription and translation.
Strategic trade-off:
Parakeet emphasizes performance efficiency, while Whisper prioritizes language coverage and robustness.
Performance Characteristics
Throughput & Latency
Parakeet v2 achieves extremely high GPU throughput, reaching ~3380× real-time factor (RTFx) in batch transcription workloads.
Whisper Large-v3 delivers significantly lower throughput (~200× RTFx) due to its larger model size and autoregressive decoding pipeline.
Accuracy
- Parakeet v2 (clean audio): ~6.0% WER
- Whisper Large-v3 (clean audio): ~8.4% WER
Whisper generally performs better in noisy and multilingual environments, while Parakeet excels in clean, high-volume English workloads.
Deployment & Integration
Parakeet v2
- Optimized for NVIDIA GPU infrastructure
- Integrated with NVIDIA Riva
- Accelerated using TensorRT
- Ideal for large-scale, production-grade ASR pipelines
Whisper
- Deployable locally or via OpenAI APIs
- ONNX and quantized variants available
- Suitable for rapid experimentation and flexible deployment

Parakeet v2 vs Whisper: ASR Model Comparison
| Metric | NVIDIA Parakeet v2 | OpenAI Whisper Large-v3 |
|---|---|---|
|
Parameters |
600M |
1.55B |
|
Architecture |
FastConformer + TDT |
Transformer Encoder – Decoder |
|
Training Data |
~0.5K Hrs – English |
680K Hrs – Multilingual |
|
Languages |
English Only |
~99 Languages |
|
Punctuation |
Native |
Native |
|
WER (clean) |
~6.0% |
~8.4% |
|
WER (noisy) |
8.4%@5dB |
Robust |
|
GPU Throughput |
~3380X |
~200X |
|
GPU Memory |
4–8 GB |
4–8 GB |
|
License |
CC-BY-4.0 |
Apache-2.0 |
|
Commercial Use |
Yes |
Yes |
Decoding Strategy & Timestamp Accuracy: ASR model comparison
Parakeet’s Token Duration Transducer explicitly models how long each word lasts, producing reliable word-level timestamps.
Whisper infers timestamps indirectly from token positions, which is sufficient for phrase-level alignment but may drift in long or noisy recordings.
Impact:
- Subtitles & captions → Parakeet preferred
- Analytics & diarization → Parakeet preferred
- General transcription → Both acceptable
Latency VS Throughput Trade-Off
Parakeet v2 excels in batch transcription, making it suitable for:
- Call centers
- Media archives
- Large-scale analytics
Whisper’s higher per-request latency becomes more noticeable in real-time or high-volume enterprise environments.
Hallucinations & Failure Modes: ASR model comparison
Whisper is known to hallucinate text during silence due to continuous token prediction.
Parakeet, when paired with Voice Activity Detection (VAD), avoids generating output during non-speech segments.
Mitigation strategies:
- Apply VAD
- Drop low-confidence tokens
- Enforce confidence thresholds
Use Case Recommendations for ASR Model Comparison
| Scenario | Recommended Model | Reason |
|---|---|---|
|
High – Volume English Transcription |
Parakeet v2 |
Cost + Throughput |
|
Multilingual Applications |
Whisper |
Language Coverage |
|
Real – Time Assistants |
Parakeet (RNNT) |
Low Latency |
|
Research & Experimentation |
Whisper |
Flexibility |
|
Subtitle Alignment |
Parakeet |
Word Timestamps |
|
Noisy Field Recordings |
Whisper |
Robust Training |
When NOT to Use PARAKEET v2 ❌
- Multilingual requirements
- CPU-only infrastructure
- Speech translation use cases
When NOT to Use Whisper ❌
- Massive English-only workloads
- Strict low-latency systems
- GPU cost-sensitive pipelines
Production Architecture Comparison
Parakeet Pipeline
Audio → VAD → GPU Batch → FastConformer → TDT → Transcript + Word Timestamps
Whisper Pipeline
Audio → Pre-Processing → Encoder → Autoregressive Decoder → Transcript
Core Difference:
- Parakeet optimizes inference efficiency.
- Whisper optimizes representational generalization.
Conclusion: ASR model comparison
Parakeet v2 is an engineering-optimized ASR system built for speed, scale, and precision in English transcription.
Whisper is a research-driven, multilingual ASR model, optimized for robustness and global language support.
At Logassa LLC, we help enterprises choose ASR architectures based on production constraints, cost models, and long-term scalability, not just benchmark scores.
👉 The best time to start was yesterday. The second-best time is today-with Logassa Inc and our advanced AI solutions.